eulerr under the hood
Johan Larsson
2026-07-01
Source:vignettes/under-the-hood.Rmd
under-the-hood.RmdIntroduction
eulerr relies on an extensive machinery to turn user input into a pretty Euler diagram. Little of this requires any tinkering from the user. To make that happen, however, eulerr needs to make several well-formed decisions about the design of the diagram on behalf of the user, which is not a trivial task.
This document outlines the implementation of eulerr from input to output. It is designed to be an evolving documentation on the innards of the program.
Input
Euler diagrams present relationships between sets, wherefore the data must describe these relationships, either directly or indirectly. eulerr allows several alternatives for this data, namely,
intersections and relative complements
unions and identities
a matrix of binary (or boolean) indices,
a list of sample spaces
-
or a two- or three-way table
1 2 3 0
As an additional feature for the matrix form, the user may supply a factor variable with which to split the data set before fitting the diagram, which sometimes improves diagrams where the set relationships vary across categories.
Whichever type of input is provided, eulerr will translate it to the first and second types, intersections and relative complements and unions and identities, which will be used in the steps to come.
The Euler diagram is then fit in two steps: first, an initial layout is formed with circles using only the sets’ pairwise relationships. Second, this layout is fine-tuned taking all intersections into consideration.
Initial layout
For our initial layout, we adopt a constrained version of multi-dimensional scaling (MDS) that has been adapted from venn.js (Frederickson 2016), which in turn is a modification of an algorithm used in venneuler (Wilkinson 2012). In it, we consider only the pairwise intersections between sets, attempting to position their respective shapes so as to minimize the difference between the separation between their centers required to obtain an optimal overlap and the actual overlap of the shapes in the diagram.
This problem is unfortunately intractable for ellipses, being that there is an infinite number of ways by which we can position two ellipses to obtain a given overlap. Thus, we restrict ourselves to circles in our initial layout, for which we can use the circle–circle overlap formula to numerically find the required distance, , for each pairwise relationship.
where and are the radii of the circles representing the th and th sets respectively, their overlap, and their separation.
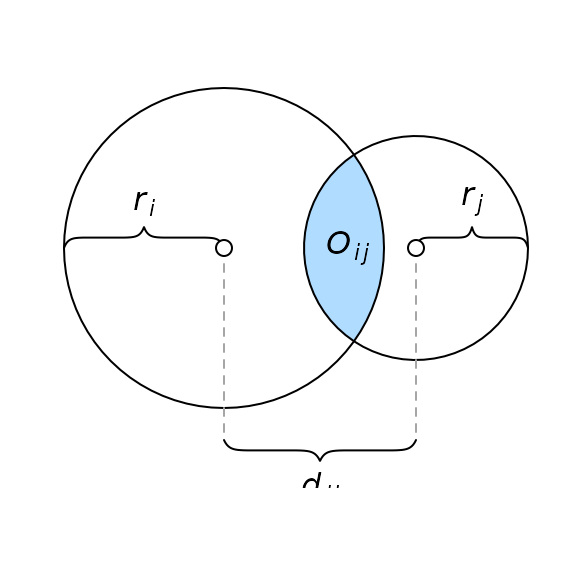
The circle–circle overlap is computed as a function of the discs’ separation (), radii (), and area of overlap ().
Setting , where is the size of the th set, we are able to obtain numerically using the squared difference between and the desired overlap as loss function,
which we optimize using optimize()1
For a two-set combination, this is all we need to plot an exact diagram, given that we now have the two circles’ radii and separation and may place the circles arbitrarily as long as their separation, , remains the same. This is not, however, the case with more than two sets.
With three or more sets, the circles need to be arranged so that they interfere minimally with one another. In some cases, the set configuration allows this to be accomplished flawlessly, but often, compromises must me made. As is often the case in this context, this turns out to be another optimization problem. It can be tackled in many ways; eulerr’s approach is based on a method developed by Frederickson (2015), which the author describes as constrained multi-dimensional scaling.
The algorithm tries to position the circles so that the separation between each pair of circles matches the separation required from the separation equation. If the two sets are disjoint, however, the algorithm is indifferent to the relative locations of those circles as long as they do not intersect. The equivalent applies to subset sets: as long as the circle representing the smaller set remains within the larger circle, their locations are free to vary. In all other cases, the loss function is the residual sums of squares of the optimal separation of circles, , that we found in the overlap equation, and the actual distance in the layout we are currently exploring.
The analytical gradient is retrieved as usual by taking the derivative of the loss function,
where is found as in the gradient with swapped for (and vice versa).
The Hessian for our loss function is given next. However, because the current release of R suffers from a bug2 causing the analytical Hessian to be updated improperly, the current release of eulerr instead relies on the numerical approximation of the Hessian offered by the optimizer.
$$ \small \mathbf{H}(h,k) = \ell{\sum_{1\leq i<j\leq N}} \begin{bmatrix} 4\left(\left(h_i-h_j\right)^2+\left(k_i-k_j\right)^2-d_{ij}^2\right)+8\left(h_i-h_j\right)^2 & \cdots & 8\left(h_i-h_j\right)\left(k_i-k_j\right)\\ \vdots & \ddots & \vdots \\ 8\left(k_i-k_j\right)\left(h_i-h_j\right) & \cdots & 4\left(\left(h_i-h_j\right)^2+\left(k_i-k_j\right)^2-d_{ij}^2\right)+8\left(k_i-k_j\right)^2 \end{bmatrix}. $$
Note that the constraints given in loss and gradients still apply to each element of the Hessian and have been omitted for convenience only.
We optimize the loss function using the nonlinear optimizer
nlm() from the R core package stats. The
underlying code for nlm was written by Schnabel et al. (1985). It was ported to R by
Saikat DebRoy and the R Core team (R Core Team
2017) from a previous FORTRAN to C translation by Richard H.
Jones. nlm() consists of a system of Newton-type algorithms
and performs well for difficult problems (Nash
2014).
The initial layout outlined above will sometimes turn up perfect diagrams, but only reliably so when the diagram is completely determined by its pairwise intersections. More pertinently, we have not yet considered the higher-order intersections in our algorithm and neither have we approached the problem of using ellipses—as we set out to do.
Final layout
We now need to account for all the sets’ intersections and, consequently, all the overlaps in the diagram. The goal is to map each area uniquely to a subset of the data from the input and for this purpose we will use the sets’ intersections and the relative complements of these intersections, for which we will use the shorthand . We introduced this form in the input section, but now define it rigorously.
For a family of N sets, , and their intersections, we define as the intersections of these sets and their relative complements, such that
with
Analogously to , we also introduce the -operator, such that
The fitted diagram’s area-equivalents for will be defined as , so that an exact diagram requires that for , where is the number of sets in the input.
In our initial configuration, we restricted ourselves to circles but now extend ourselves also to ellipses. From now on, we abandon the practice of treating circles separately—they are only a special case of ellipses, and, hence, everything that applies to an ellipse does so equally for a circle.
Intersecting ellipses
We now need the ellipses’ points of intersections. eulerr’s approach to this is outlined in (Richter-Gebert 2011) and based in projective, as opposed to Euclidean, geometry.
To collect all the intersection points, we naturally need only to consider two ellipses at a time. The canonical form of an ellipse is given by
where is the counter-clockwise angle from the positive x-axis to the semi-major axis , is the semi-minor axis, and are the x- and y-coordinates, respectively, of ellipse’s center.
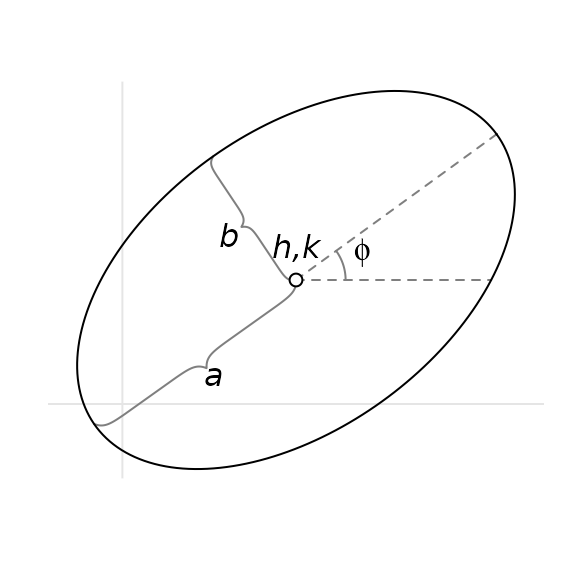
A rotated ellipse with semimajor axis , semiminor axis , rotation , and center .
However, because an ellipse is a conic3 it can be represented in quadric form,
that in turn can be represented as a matrix,
which is the form we need to intersect our ellipses. We now proceed to form three degenerate conics from a linear combination of the two ellipses we wish to intersect, split one of these degenerate conics into two lines, and intersect one of the ellipses with these lines, yielding 0 to 4 intersection points points.


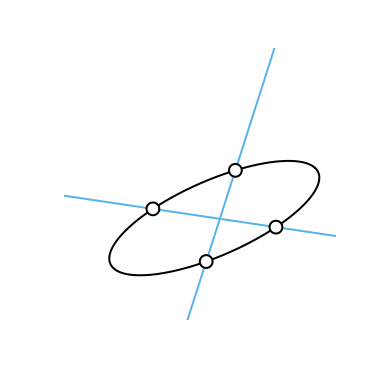
The process used to intersect two ellipses, here yielding four points. This figure was inspired by an example from Richter–Gebert 2011.
Overlap areas
Using the intersection points of a set of ellipses that we retrieved in, we can now find the overlap of these ellipses. We are only interested in the points that are contained within all of these ellipses, which together form a geometric shape consisting of a convex polygon, the sides of which are made up of straight lines between consecutive points, and a set of elliptical arcs—one for each pair of points.

The overlap area between three ellipses is the sum of a convex polygon (in grey) and 2–3 ellipse segments (in blue).
We continue by ordering the points around their centroid. It is then trivial to find the area of the polygon section since it is always convex. Now, because each elliptical segment is formed from the arcs that connect successive points, we can establish the segments’ areas algorithmically (Eberly 2016). For each ellipse and its related pair of points (located at angles and from the semimajor axis), we proceed to find its area by
- centering the ellipse at ,
- normalizing its rotation, which is not needed to compute the area,
- integrating the ellipse over [] and [], producing elliptical sectors and ,
- subtracting the smaller ()) of these sectors from the larger (), and
- subtracting the triangle section to finally find the segment area, where
This procedure is illustrated in the following figure. Note that there are situations where this algorithm is altered, such that when the sector angle ranges beyond —we refer the interested reader to Eberly (2016).
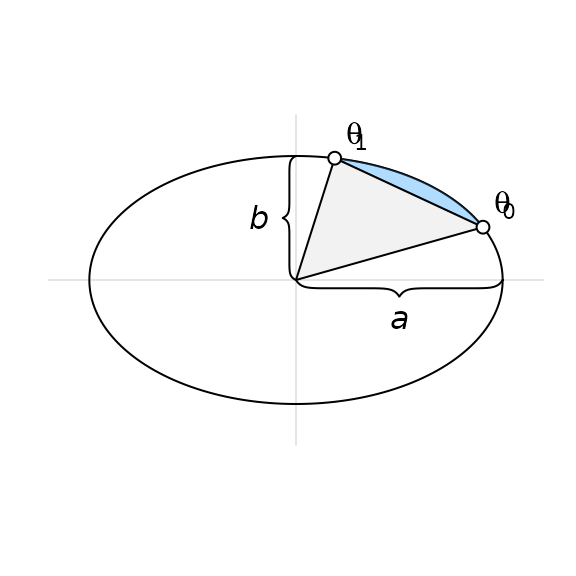
The elliptical segment in blue is found by first subtracting the elliptical sector from to from the one from to and then subtracting the triangle part (in grey).
Finally, the area of the overlap is then obtained by adding the area of the polygon and all the elliptical arcs together.
Note that this does not yet give us the areas that we require, namely : the area-equivalents to the set intersections and relative complements from our definition of the intersections. For this, we must decompose the overlap areas so that each area maps uniquely to a subspace of the set configuration. This, however, is simply a matter of transversing down the hierarchy of overlaps and subtracting the higher-order overlaps from the lower-order ones. For a three-set relationship of sets , , and , for instance, this means subtracting the overlap from the one to retrieve the equivalent of .
The exact algorithm may in rare instances4, break down, the culprit being numerical precision issues that occur when ellipses are tangent or completely overlap. In these cases, the algorithm will approximate the area of the involved overlap by
- spreading points across the ellipses using Vogel’s method.
- identifying the points that are inside the intersection via the inequality where and are the coordinates of the sampled points, and finally
- approximating the area by multiplying the proportion of points inside the overlap with the area of the ellipse.
With this in place, we are now able to compute the areas of all intersections and their relative complements, , up to numerical precision.
Final optimization
We feed the initial layout to the optimizer—once again we employ
nlm() from stats but now also provide the
option to use ellipses rather than circles, allowing the “circles” to
rotate and the relation between the semiaxes to vary, altogether
rendering five parameters to optimize per set and ellipse (or three if
we restrict ourselves to circles). For each iteration of the optimizer,
the areas of all intersections are analyzed and a measure of loss
returned. The loss we use is the same as in venneuler
(Frederickson 2016), namely the residual
sums of squares.
If the fitted diagram is still inexact after the procedure, we offer a final step in which we pass the parameters on to a last-ditch optimizer. The weapon of choice5 is stress (Wilkinson 2012), which is also the loss metric we use in our final optimization step and is used in venneuler, as well as diagError (Micallef and Rodgers 2014), which is used by eulerAPE.
The stress metric is not easily grasped but can be transformed into a rough analogue of the correlation coefficient via .
diagError, meanwhile, is given by
which is the maximum absolute difference of the proportion of any to the respective unique area of the diagram.